LLM Native Primitives: Next Golden Path
“Primitives are the raw parts or the most foundational-level building blocks for software developers. They’re indivisible (if they can be functionally split into two they must) and they do one thing really well. They’re meant to be used together rather than as solutions in and of themselves. And, we’ll build them for maximum developer flexibility. We won’t put a bunch of constraints on primitives to guard against developers hurting themselves. Rather, we’ll optimize for developer freedom and innovation.” - 2003 AWS Vision document
"Transformer" turns 8, Cloud Native Computing Foundation (CNCF) turns 10 (refer post), Kubernetes, Lambda, ECS and Alexa turn 11, Bedrock and Claude turn 2. The shift from CPU-native to LLM/GPU-native applications has begun. What's the next golden path for this era ?
LLMs vs Other Apps
I spent two years working on SOTA LLM inference, both closed-source models (Anthropic) and open-source models (Llama and DeepSeek). More recently, I transitioned concentration on model optimization and inference acceleration. The closer you get to the models themselves, the more you realize how non-trivial it is to run and optimize them effectively.
Red Hat AI's tweets "LLM inference is too slow, too expensive, and too hard to scale." provided an in-depth descriptions of those challenges.
| LLMs Apps Workloads | Other Apps Workloads |
|---|---|
|
|
|
Peter DeSantis had an excellent keynote in re:Invent 2024 that highlighted "AI workloads are Scale up workloads. Larger models demand more compute. Science and algorithmic limitations decide simple scale out doesn't work."
Last Mile Delivery
Lately, I’ve seen a flourishing of open-source large model inference frameworks (like llm-d, Dynamo, SGLang..), as well as caching projects such as LMCache, Mooncake, and engines TensorRT, vLLM. Looking back to early 2023, when running a GPU felt like lugging bricks, it’s clear that LLM inference and optimization are now starting to coalesce around some fuzzy but emerging industry-standard paradigms. As someone who’s been hands-on with large model serving for two years, I find this really encouraging.
Although this area doesn’t have the academic depth or community influence of blogs from respected researchers like Lilian Weng or Shunyu Yao, and it lacks the accessibility and popularity of agent-level applications, it still plays a vital role. It’s hard to classify, it's not the model itself, not the application layer, not infrastructure, and not hardware either. It’s perhaps closest in relationship to MCP vs agents and K8s vs CPU. Sitting between the model and the hardware, you could call this the 'middleware layer.'
This middleware layer aims to tackle the real bottlenecks that stand in the way of deploying LLMs at scale: “LLM inference is too slow, too expensive, and too hard to scale.”
These are ‘last mile’ problems, making LLMs run efficiently, reliably, and elastically, and turning model capabilities into real user value. What’s more, nearly every project in this space is choosing open-source collaboration as the path forward, which is incredibly welcoming for those who are passionate about contributing to open-source communities. It feels a lot like the early days of public cloud 10 years ago: from CPU → virtualization → VM → containers → serverless.
The LLM/GPU-native era has begun.
Next Golden Path
At Amazon, there's an internal concept known as 'the golden path', a set of opinionated best practice tooling, architecture, and configuration recommendations for the end-to-end builder experiences, popular options like AWS Lambda and ECS/Fargate. As all CPU-native apps and platforms passed decade, what's the golden path for LLM-native applications?
Communities appear to have already draw a few lines:
...
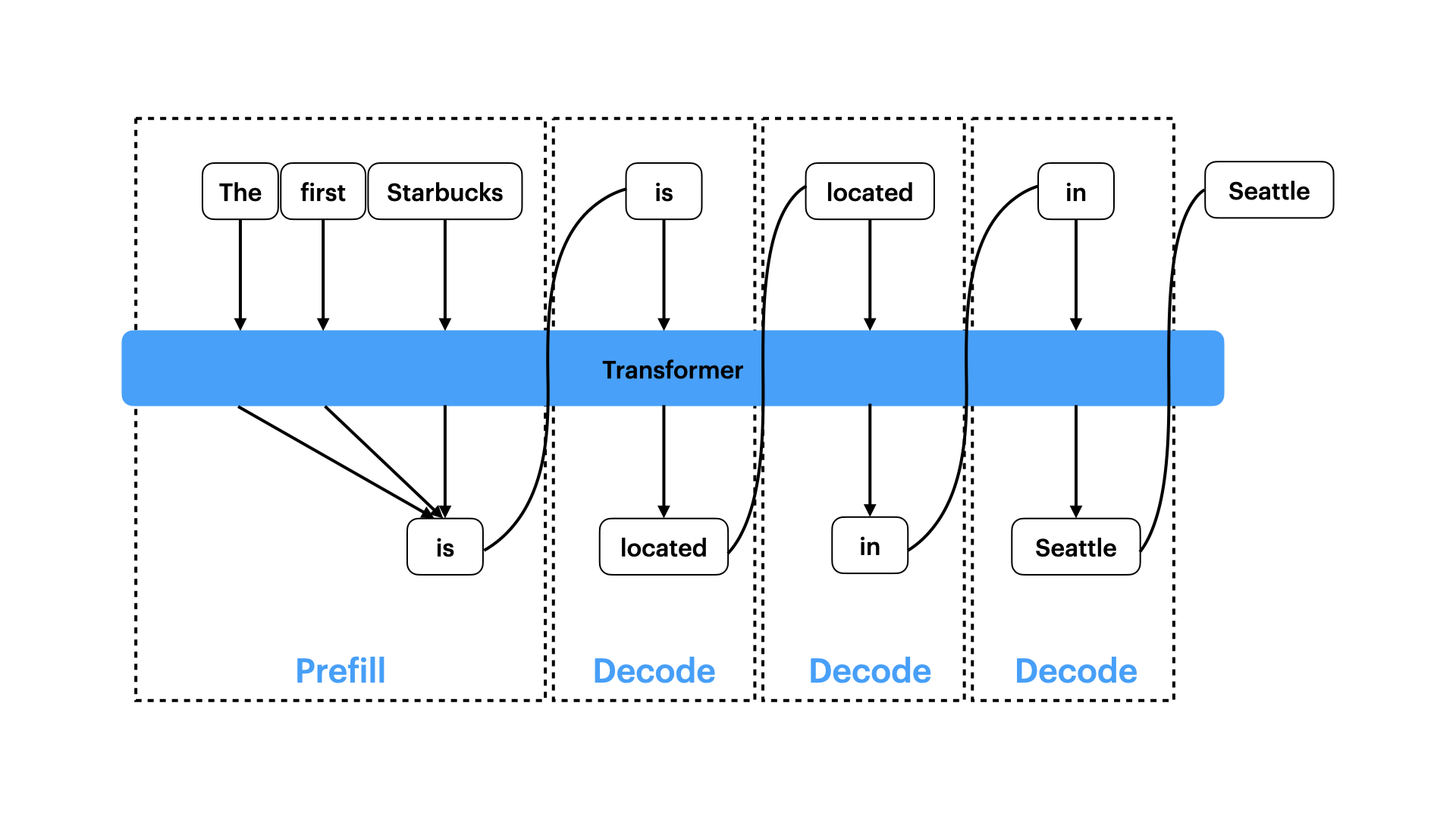
Figure: Prefill and Decode Phases of the Transformer
Now the model itself differentiation is shrinking, in the future, this area will become one of key differentiators: how to run models better.
Rather than picking one or two specific software solutions, while waiting the next K8s timing coming, I prefer to talk about a new working model where Product, Engineering, and Research collaborate more closely than ever before. This kind of integration, unlike anything we've seen in the past, is just beginning to take shape. vLLM is a representative example. And the future remains wide open.
